
by Dr. Georg SOMMER
Ziel des Projekts/Unterrichts ist es, natürliche Sprache in Texten, Blogs, Kommentaren, etc mittels Methoden des NLP (Natural Language Processing) zu verarbeiten.
Im Speziellen sollen dabei Twitter Messages (Tweets) darauf untersucht werden, ob das Vorkommen bestimmter „Katastrophenwörter“ (disaster terms) auf ein reales Ereignis zutreffen oder nur methaphorisch verwendet werden.
Dazu werden rund 10000 Trainingsdaten von Twitter-Einträgen verwendet, die per Hand klassifiziert wurden (Download: https://www.kaggle.com/competitions/nlp-getting-started/data)
Beispielhaft seien einige Trainingsdaten angeführt:

Abbildung 1: Trainingsdaten für Twittereinträge. Target: 1-Real Desaster, O- Not
Ausgangspunkt war die Datenaufbereitung mittels bewährter Methoden des NLP und IR (Information Retrival)
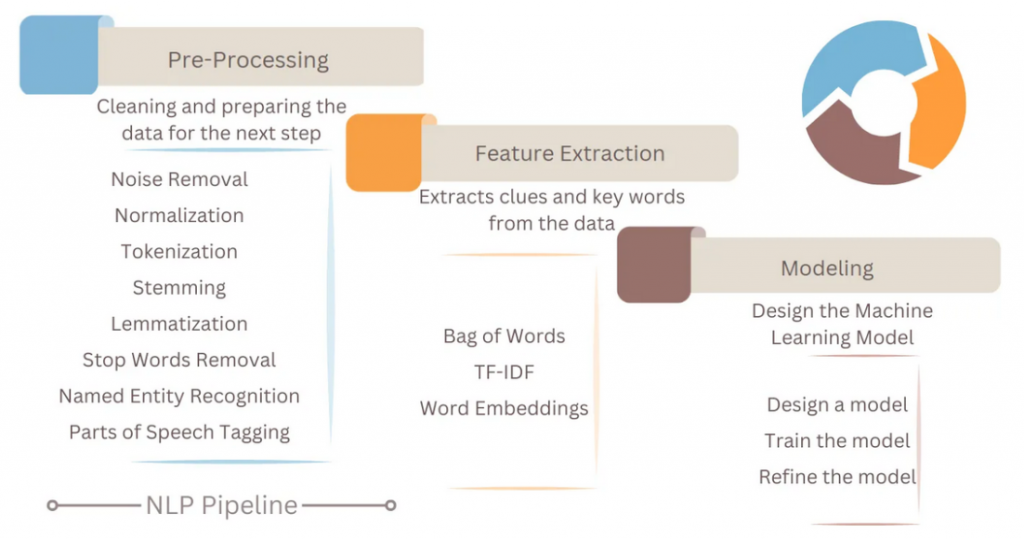
Abbildung 2: Quelle: https://medium.com/@tech-gumptions/natural-language-processing-nlp-pipeline-e766d832a1e5
Der erste Schritt in der Textanalyse ist die Bereinigung der einzelnen Tweettexte von Sonder- und Steuerzeichen, die Entfernung von Stoppworten (und, es, etc) sowie das Aufsplitten in einzelne Tokens mit Hilfe von verschiedenen Bibliotheken.

Abbildung 3:Wichtige Python Bibliotheken zur Textanalyse
Dabei werden verschiedene statistische Analysen angewandt, beispielsweise:
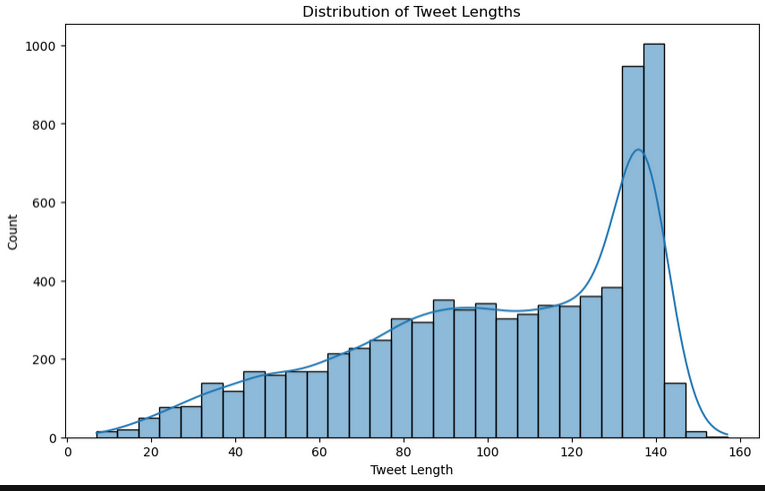
Abbildung 4:Durchschnittliche Länge von Tweets
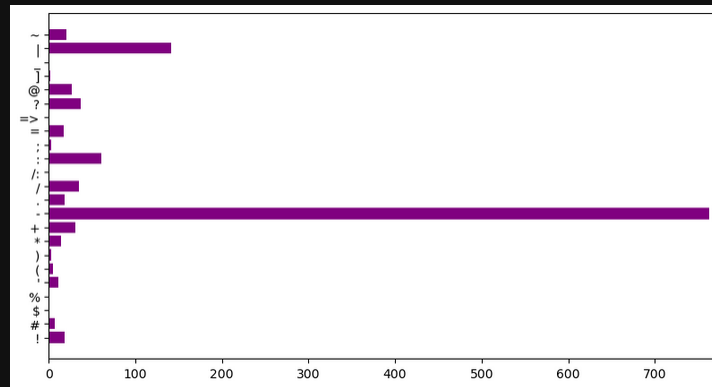
Abbildung 5: Auftreten von Sonerzeichen
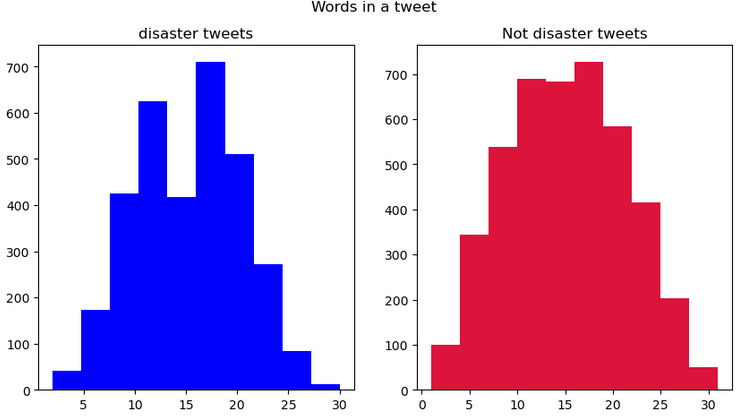
Abbildung 6: Worthäufigkeiten Verteilungen
Mittels Bag-of-Words (Anzahl der Worthäufigkeiten in den einzelnen Dokumenten und im gesamten Trainingskorpus) Modell, konnten sich jetzt verschiedene Algorthmen des Maschinellen Lernens anwenden lassen, z.B.
Naive Bayes:

Dies liefert nach einigen Optimierungsschritten im Data Preprocessing folgende Ergebnisse

ToDo’S: Weiters werden diese Tweets noch mit verschiedenen Neuronalen Netzen traininiert werden, v.a. soll noch untersucht werden, ob sich durch die Verwendung modernerer Ansätze als das Bag-of-Word Modell, auch in kurzen Textnachrichten noch Verbesserungen erzielen lassen.
Inhalte, die bislang den Schülern vermittelt werden konnten:
- Kennenlernen von Python und wichtiger Bibliotheken
- Grundlegende Arbeitsschritte im Umgang mit Textdaten
- Mathematische Darstellung von Text als Basis für statistische Analysen
- Modellbildung im Maschinellen Lernen
- Verwendung von speziellen Modellen (Bayes, SVM, Neuronale Netze) für moderne textbasierte Anwendungen (Textklassifikation, Chatbots, Übersetzungssyteme, etc)
